Sync Jira issues from Atlassian cloud to SeaTable
If you want to synchronize Jira issues from Atlassian Cloud to a SeaTable base you can do it with the following python script.
Preperation
You have to run a modified python runner since the script uses unsopported pip packages.
- JIRA
SeaTable base
- Download the two CSV-files and import them into a new Base. The tables you are about to create have to be named Settings and Issues otherweise the python script will not work!
-
Now create a new python script with the following source code
from seatable_api import Base, context from jira import JIRA from datetime import datetime from dateutil.parser import parse # connect to SeaTable server_url = context.server_url api_token = context.api_token base = Base(api_token, server_url) base.auth() # read settings from SeaTable accountDataRows = base.list_rows('Settings') projectUrl = None accountEmail = None accountToken = None searchJql = None for row in accountDataRows: if row['Key'] == 'projectUrl': projectUrl = row['Value'] elif row['Key'] == 'accountEmail': accountEmail = row['Value'] elif row['Key'] == 'accountToken': accountToken = row['Value'] elif row['Key'] == 'searchJql': searchJql = row['Value'] # get Jira issues jira = JIRA(server=projectUrl, basic_auth=(accountEmail, accountToken)) jiraIssues = jira.search_issues(searchJql) jiraKeyCount = len(jiraIssues) if jiraKeyCount >= 50000: print('SeaTable cannot query more than 50000 entries at once!') exit() jiraKeys = "'" + "', '".join([jiraIssue.key for jiraIssue in jiraIssues]) + "'" # get existing issues from SeaTable existingIssuesRows = base.query(f'select * from Issues where Key in ({jiraKeys}) limit {jiraKeyCount}') def formatDateTime(value): if value is None: return None value = parse(value) return value.strftime('%Y-%m-%d %H:%M') def strFromList(list, seperator): if list is None or len(list) == 0: return None return seperator.join([label for label in list]) def createBatchRow(jiraIssue): return { 'Key': jiraIssue.key, 'Link': jiraIssue.self, 'Summary': jiraIssue.fields.summary, 'Description': jiraIssue.fields.description, 'Issue type': jiraIssue.fields.issuetype.name, 'Labels': strFromList(jiraIssue.fields.labels, ','), 'Priority': f"{jiraIssue.fields.priority.id} - {jiraIssue.fields.priority.name}", 'Status': jiraIssue.fields.status.name, 'Creator': f"{jiraIssue.fields.creator.displayName} ({jiraIssue.fields.creator.emailAddress})", 'Reporter': f"{jiraIssue.fields.reporter.displayName} ({jiraIssue.fields.reporter.emailAddress})", 'Created': formatDateTime(jiraIssue.fields.created), 'Last viewed': formatDateTime(jiraIssue.fields.lastViewed), 'Updated': formatDateTime(jiraIssue.fields.updated), } batchUpdate = [] batchAppend = [] # run through all Jira issues and do add or update for jiraIssue in jiraIssues: found = False for exIssue in existingIssuesRows: if exIssue['Key'] != jiraIssue.key: continue found = True batchUpdate.append({ 'row_id': exIssue['_id'], 'row': createBatchRow(jiraIssue), }) break if not found: batchAppend.append(createBatchRow(jiraIssue)) if len(batchUpdate) > 0: base.batch_update_rows('Issues', rows_data=batchUpdate) if len(batchAppend) > 0: base.batch_append_rows('Issues', rows_data=batchAppend) -
If you have imported all files and scripts you have to update the settings table with your data from Atllasian Jira cloud.
-
projectUrl https://???.atlassian.net accountEmail my@email.com accountToken account_token searchJql project = ???
- Now you should be able to execute the script and find all your Jira issues in the Issues table.
Workflow with n8n
Another way to update this data is to run a n8n-workflow that is triggerd automatically by Jira and periodically by cronjob.
Not every field is read but you can still modify the workflow.
The steps "If any field is different", "Update issues" and "Add new issues" contain field assignments.
With the step "Modify values" you can combine fields from Jira like Priority where you want to have id "3" and name "Medium" combined to "3 - Medium".
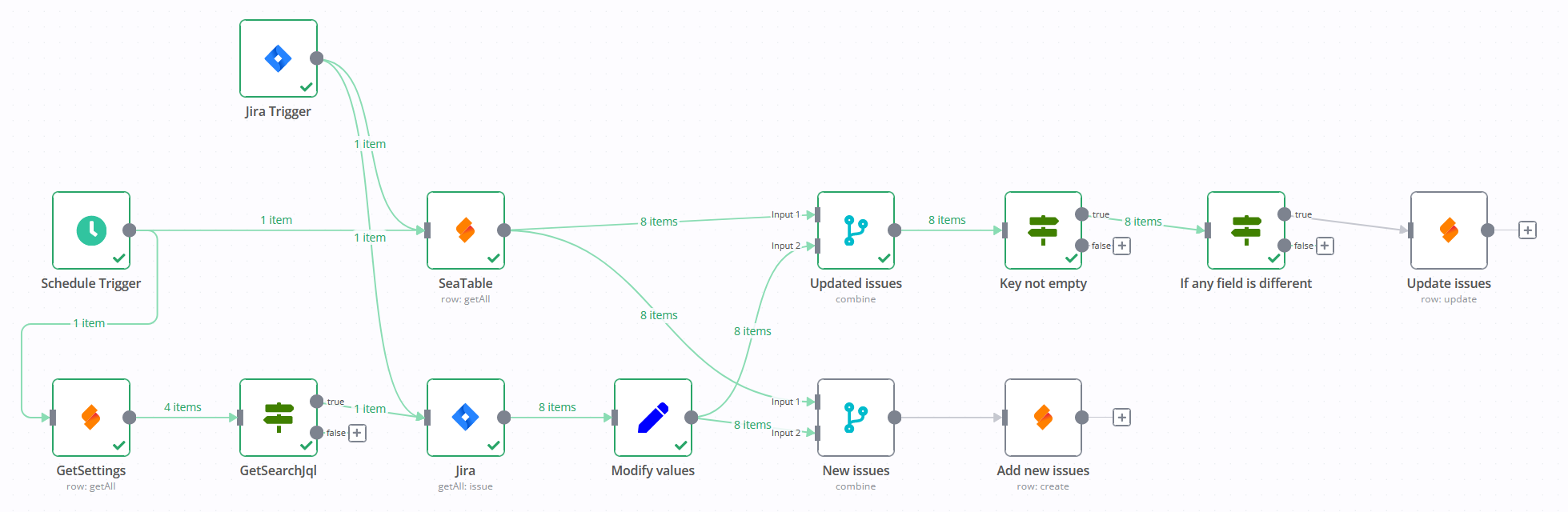
You can download the workflow n8n-Jira-SeaTable.json.
No comments to display
No comments to display